
1. 下载ollama应用程序安装包已经放在操作一的文件夹内
备注;如果遇到安装包更新情况,请去官方搜索下载。ollama只能安装c盘
官方网址:https://ollama.com/download/windows
国内地址:https://www.gy328.com/app/ollama/(国外可能下载过慢)
2. 安装ollama应用程序,安装成功之后去官方网址搜索deepseek R1

搜索之后确认进入到deepseek R1大模型的选择
由于电脑配置的不同(看的是APU(显卡)的算力和内存大小,请看下面的表格
|
deepseek大模型选取 |
|||||
|
类别 |
推荐cpu |
内存 |
硬盘大小 |
显卡 |
|
|
DeepSeek-R1-1.5B |
最低 4 核(推荐 Intel/AMD 多核处理器) |
8GB+ |
3GB+ 存储空间(模型文件约 1.5-2GB) |
非必需(纯 CPU 推理),若 GPU 加速可选 4GB+ 显存(如 GTX 1650) |
低资源设备部署(如树莓派、旧款笔记本) |
|
DeepSeek-R1-7B |
8 核以上(推荐现代多核 CPU) |
16GB+ |
8GB+(模型文件约 4-5GB) |
推荐 8GB+ 显存(如 RTX 3070/4060) |
本地开发测试(中小型企业) |
|
DeepSeek-R1-8B |
与 7B 相近,略高 10-20% |
7B 相近 |
7B 相近 |
7B 相近 |
需更高精度的轻量级任务(如代码生成、逻辑推理) |
|
DeepSeek-R1-14B |
12 核以上 |
32GB+ |
15GB+ |
16GB+ 显存(如 RTX 4090 或 A5000) |
企业级复杂任务(合同分析、报告生成) |
|
DeepSeek-R1-32B |
16 核以上(如 AMD Ryzen 9 或 Intel i9) |
64GB+ |
30GB+ |
24GB+ 显存(如 A100 40GB 或双卡 RTX 3090) |
高精度专业领域任务(医疗/法律咨询) |
|
DeepSeek-R1-70B |
32 核以上(服务器级 CPU) |
128GB+ |
70GB+ |
多卡并行(如 2x A100 80GB 或 4x RTX 4090) |
科研机构/大型企业(金融预测、大规模数据分析) |
|
DeepSeek-R1-671B |
64 核以上(服务器集群) |
512GB+ |
300GB+ |
多节点分布式训练(如 8x A100/H100) |
国家级/超大规模 AI 研究(如气候建模、基因组分析) |
3. 以DeepSeek-R1-8B为例:
复制代码

Win+R打开cmd指令集(win10-win11可以选择终端)
粘贴到cmd(终端)敲回车

看到运行(下载中)就是以上操作步骤全部正确

安装完成是这个界面:

现在deepseek已经完全本地化的部署在你的电脑上,现在你可以在你的cmd(终端)里和你的ai聊天了

虽然本地化的部署了ai大模型和成功的使用了,但是就出现了两个极大的弊端:
1:如果二次调用你的模型进行对话,就要输入在刚开始部署的那个代码

2:界面丑陋,而且操作相对麻烦(本来就是用大模型来便携自己的,结果刚开始就不便携)
所以就用到了开源的chatbox(其他的聊天框也可以使用,但是大部分的聊天框不是安装,是部署,所以比较麻烦,chatbox是像软件一样安装,不会出现像其他聊天框部署一步错步步错的情况)
聊天框chatbox的使用
1:打开步骤2的文件夹安装chatbox(必须安装c盘,不然会安装报错)
2:按照图片开始操作


备注:千万不要选择deepseek api,因为它检索不到你电脑里的大模型,一定要选择ollama api
3:选择你安装在电脑里的大模型
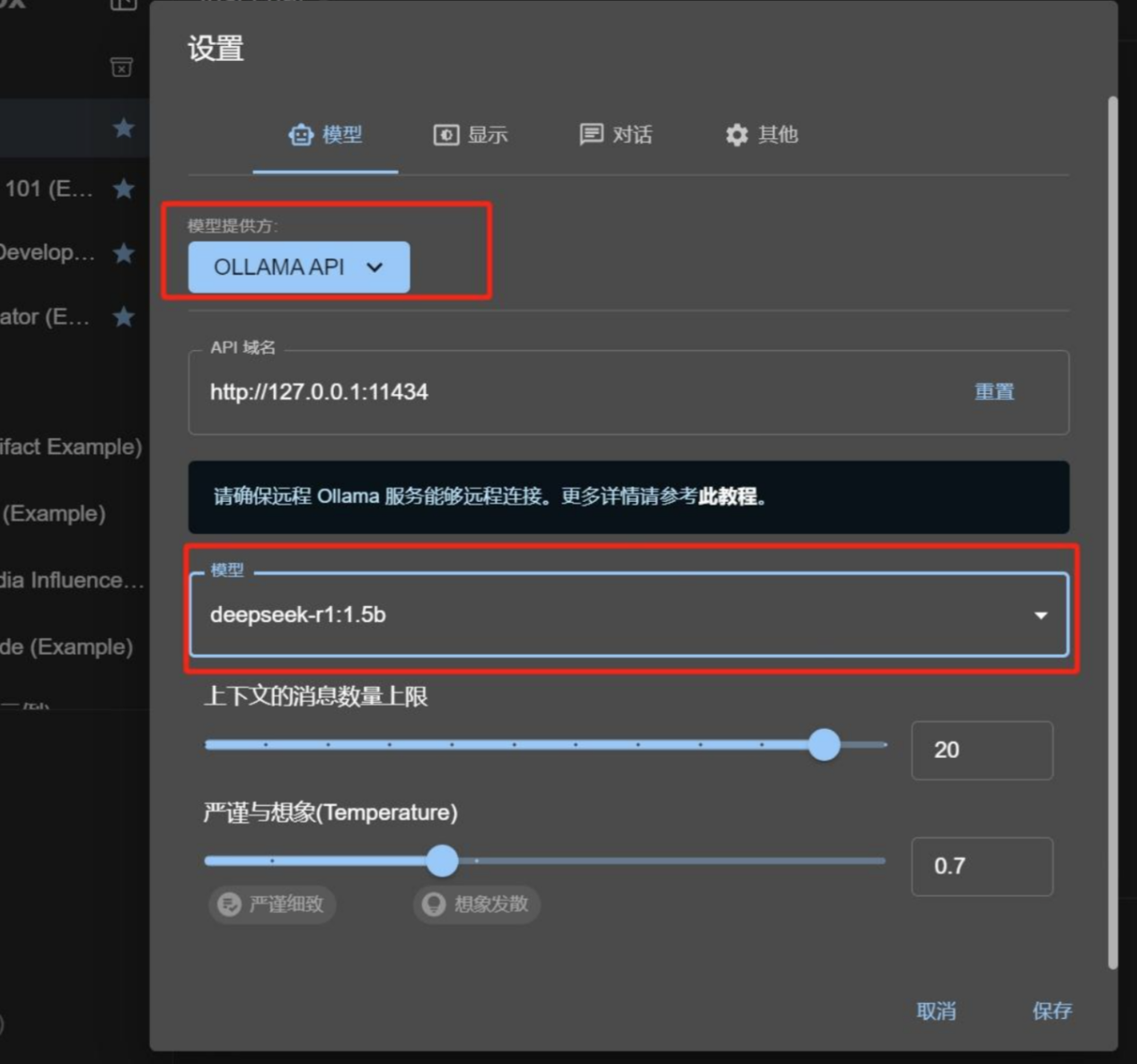
Api域名不用设置,它会自己跳出来
4:之后点击新对话新建一个(自带的聊天框没用就删,因为回复太慢,用的不是你的大模型,用的是云端)
之后你的私人助理的完美的配置好了
效果:


发表评论